ProgramingComments Off on Viết bash scipt check logs nodejs realtime
Feb142023
Để kiểm tra log của ứng dụng NodeJS trong thời gian thực và gửi cảnh báo qua Telegram nếu xuất hiện dòng log “error”, bạn có thể sử dụng script bash kết hợp với lệnh tail và grep. Dưới đây là một ví dụ:
#!/bin/bash
# Set the Telegram bot token and chat ID
TELEGRAM_BOT_TOKEN="your_bot_token"
TELEGRAM_CHAT_ID="your_chat_id"
# Set the path to the log file
LOG_FILE_PATH="/path/to/your/logfile.log"
# Set the polling interval (in seconds)
POLLING_INTERVAL=10
# Run an infinite loop
while true; do
# Get the last line of the log file that contains the word "error"
last_error_line=$(tail -n 1 "$LOG_FILE_PATH" | grep "error")
# Check if the last error line is not empty
if [ -n "$last_error_line" ]; then
# Send a Telegram message
message="ERROR: $last_error_line"
curl -s -X POST "https://api.telegram.org/bot${TELEGRAM_BOT_TOKEN}/sendMessage" -d "chat_id=${TELEGRAM_CHAT_ID}" -d "text=$message"
fi
# Wait for the polling interval
sleep $POLLING_INTERVAL
done
Giải thích các bước trong script:
Thiết lập mã thông báo bot Telegram và ID trò chuyện.
Thiết lập đường dẫn đến tệp nhật ký.
Thiết lập khoảng thời gian giữa các lần kiểm tra tệp nhật ký.
Chạy một vòng lặp vô hạn để kiểm tra tệp nhật ký.
Sử dụng lệnh tail để lấy dòng cuối cùng của tệp nhật ký.
Sử dụng lệnh grep để kiểm tra xem dòng cuối cùng có chứa từ “error” không.
Nếu có lỗi, gửi thông báo qua Telegram bằng cách sử dụng curl để gọi API Telegram.
Chờ trong khoảng thời gian giữa các lần kiểm tra tệp nhật ký bằng lệnh sleep.
ProgramingComments Off on Bash script kiểm tra disk, cpu, ram trên máy chủ linux
Feb142023
Để kiểm tra tình trạng ổ đĩa, CPU và RAM trên máy chủ Linux và cảnh báo khi vượt quá giới hạn cấu hình thông qua Telegram, bạn có thể sử dụng script bash dưới đây:
#!/bin/bash
# Set the threshold for disk, CPU, and RAM usage
DISK_THRESHOLD=80 # in %
CPU_THRESHOLD=80 # in %
RAM_THRESHOLD=80 # in %
# Set the Telegram bot token and chat ID
TELEGRAM_BOT_TOKEN="your_bot_token"
TELEGRAM_CHAT_ID="your_chat_id"
# Check disk usage and send a warning if it exceeds the threshold
disk_usage=$(df -h / | awk '/\// {print $(NF-1)}' | sed 's/%//')
if [ "$disk_usage" -ge "$DISK_THRESHOLD" ]; then
message="WARNING: Disk usage is at ${disk_usage}%"
curl -s -X POST "https://api.telegram.org/bot${TELEGRAM_BOT_TOKEN}/sendMessage" -d "chat_id=${TELEGRAM_CHAT_ID}" -d "text=$message"
fi
# Check CPU usage and send a warning if it exceeds the threshold
cpu_usage=$(top -b -n 1 | awk '/^%Cpu/ {print $2}' | cut -d '.' -f 1)
if [ "$cpu_usage" -ge "$CPU_THRESHOLD" ]; then
message="WARNING: CPU usage is at ${cpu_usage}%"
curl -s -X POST "https://api.telegram.org/bot${TELEGRAM_BOT_TOKEN}/sendMessage" -d "chat_id=${TELEGRAM_CHAT_ID}" -d "text=$message"
fi
# Check RAM usage and send a warning if it exceeds the threshold
ram_usage=$(free | awk '/^Mem/ {print $3/$2 * 100.0}' | cut -d '.' -f 1)
if [ "$ram_usage" -ge "$RAM_THRESHOLD" ]; then
message="WARNING: RAM usage is at ${ram_usage}%"
curl -s -X POST "https://api.telegram.org/bot${TELEGRAM_BOT_TOKEN}/sendMessage" -d "chat_id=${TELEGRAM_CHAT_ID}" -d "text=$message"
fi
Giải thích các bước trong script:
Thiết lập ngưỡng cho việc sử dụng đĩa, CPU và RAM.
Thiết lập mã thông báo bot Telegram và ID trò chuyện.
Kiểm tra việc sử dụng đĩa và gửi cảnh báo nếu nó vượt quá ngưỡng.
Kiểm tra việc sử dụng CPU và gửi cảnh báo nếu nó vượt quá ngưỡng.
Kiểm tra việc sử dụng RAM và gửi cảnh báo nếu nó vượt quá ngưỡng.
Để thực hiện việc backup GitLab và lưu bản sao lưu có tên chứa ngày tháng năm, giữ lại 3 bản sao lưu mới nhất và sao chép bản sao lưu mới nhất sang máy chủ khác thông qua ssh key, bạn có thể sử dụng script bash sau:
#!/bin/bash
# GitLab backup directory
backup_dir="/var/opt/gitlab/backups/"
# Create the backup directory if it doesn't exist
if [ ! -d "$backup_dir" ]; then
mkdir -p "$backup_dir"
fi
# Backup GitLab and name the backup file with the current date and time
backup_file="$backup_dir$(date +%Y-%m-%d_%H-%M-%S)_gitlab_backup.tar"
gitlab-rake gitlab:backup:create BACKUP=$backup_file
# Keep only the 3 most recent backups and delete the rest
cd "$backup_dir"
ls -t | grep -v -E "$(ls -t | head -n 3 | sed 's/$/|/' | tr -d '\n')" | xargs rm -f
# Copy the newest backup file to another server via ssh key
remote_server="user@remote-server"
remote_backup_dir="/var/opt/gitlab/backups/"
newest_backup_file=$(ls -t | head -n 1)
scp -i /path/to/ssh/key "$backup_dir$newest_backup_file" "$remote_server:$remote_backup_dir"
Giải thích các bước trong script:
Thiết lập đường dẫn cho thư mục sao lưu GitLab.
Kiểm tra xem thư mục sao lưu đã tồn tại chưa, nếu không thì tạo mới thư mục.
Thực hiện sao lưu GitLab và đặt tên tệp sao lưu theo ngày giờ hiện tại.
Giữ lại chỉ 3 bản sao lưu mới nhất và xóa các bản sao lưu cũ hơn.
Sao chép tệp sao lưu mới nhất sang máy chủ khác qua ssh key, sử dụng lệnh scp.
DatabaseComments Off on Các giải pháp về database firewall
Feb142023
Các giải pháp về database firewall bao gồm:
Database Activity Monitoring (DAM): Phát hiện và ngăn chặn các hoạt động không đúng trên cơ sở dữ liệu. Ưu điểm của DAM là có thể giám sát toàn bộ hoạt động trên cơ sở dữ liệu, giúp phát hiện các hành vi tấn công một cách chính xác và có khả năng ngăn chặn các cuộc tấn công bằng cách chặn các truy cập không được phép. Nhược điểm của DAM là tác động đến hiệu suất hệ thống và có thể làm chậm tốc độ truy cập dữ liệu.
Database Firewall: Lọc các yêu cầu truy cập cơ sở dữ liệu bằng cách so sánh với các quy tắc bảo mật được cấu hình trước đó. Ưu điểm của database firewall là có khả năng phát hiện và ngăn chặn các cuộc tấn công trên cơ sở dữ liệu, đồng thời cải thiện hiệu suất hệ thống bằng cách chỉ cho phép các truy cập được phép và từ chối các truy cập không được phép. Nhược điểm của database firewall là việc cấu hình các quy tắc bảo mật phức tạp và thường đòi hỏi nhiều thời gian và nguồn lực.
Database Encryption: Mã hóa dữ liệu trong cơ sở dữ liệu để bảo vệ dữ liệu khỏi bị đánh cắp hoặc xem trộm. Ưu điểm của database encryption là có khả năng bảo vệ dữ liệu quan trọng của tổ chức, ngăn chặn các cuộc tấn công gián đoạn hoạt động của cơ sở dữ liệu. Nhược điểm của database encryption là có thể ảnh hưởng đến hiệu suất hệ thống khi phải mã hóa và giải mã dữ liệu trên cơ sở dữ liệu.
Data Masking: Ẩn giấu các thông tin nhạy cảm trong cơ sở dữ liệu để bảo vệ dữ liệu khỏi bị đánh cắp hoặc xem trộm. Ưu điểm của data masking là giúp bảo vệ dữ liệu quan trọng của tổ chức, đồng thời giúp người dùng thực hiện các công việc đòi hỏi truy cập dữ liệu mà không bị phát hiện. Nhược điểm của data masking là có thể giảm hiệu quả của các ứng dụng dựa trên cơ sở dữ liệu.
Database Auditing: Theo dõi các hoạt động trên cơ sở dữ liệu và tạo báo cáo để phát hiện các hành vi tấn công. Ưu điểm của database auditing là giúp phát hiện các hoạt động bất thường trên cơ sở dữ liệu, đồng thời cung cấp thông tin chi tiết về các hành vi truy cập dữ liệu để phục vụ cho quản lý bảo mật. Nhược điểm của database auditing là có thể làm chậm tốc độ truy cập dữ liệu và tăng tải cho hệ thống.
Data Loss Prevention (DLP): Phát hiện và ngăn chặn mất dữ liệu trên cơ sở dữ liệu. Ưu điểm của DLP là có khả năng phát hiện và ngăn chặn các cuộc tấn công tìm cách lấy cắp dữ liệu quan trọng của tổ chức. Nhược điểm của DLP là việc cấu hình và triển khai đòi hỏi nhiều thời gian và nguồn lực, đồng thời có thể gây ra sự cố nếu như hệ thống DLP không hoạt động chính xác.
Database Isolation: Phân tách các phần khác nhau của cơ sở dữ liệu để đảm bảo an toàn và bảo mật. Ưu điểm của database isolation là đảm bảo rằng dữ liệu quan trọng được giữ an toàn và được phân bố một cách rõ ràng trong hệ thống cơ sở dữ liệu. Nhược điểm của database isolation là có thể làm tăng chi phí về quản lý cơ sở dữ liệu và làm chậm tốc độ truy cập dữ liệu.
Database Patch Management: Quản lý việc cập nhật các lỗ hổng bảo mật trên cơ sở dữ liệu để đảm bảo an toàn và bảo mật. Ưu điểm của database patch management là đảm bảo rằng cơ sở dữ liệu được bảo vệ tốt nhất và giảm thiểu rủi ro bị tấn công từ các lỗ hổng bảo mật đã biết. Nhược điểm của database patch management là có thể ảnh hưởng đến hiệu suất hệ thống và đòi hỏi sự quan tâm đến cập nhật thường xuyên của các lỗ hổng bảo mật.
Tổng kết lại, các giải pháp về database firewall đều có những ưu điểm và nhược điểm riêng.
BlockChainComments Off on Sự khác biệt giữa Permissioned và Permissionless Blockchain
Oct082019
Một trong những phần lớn nhất trong công nghệ blockchain chính là permissioned blockchain (blockchain được cấp phép hay blockchain đóng) và permissionless blockchain (blockchain không cần cấp phép hay blockchain mở). Sự khác biệt cơ bản khá rõ ràng: Bạn cần phê duyệt để sử dụng một permissioned blockchain, trong khi bất kỳ ai cũng có thể tham gia vào các hệ thống không cần cấp phép (permissionless). Ví dụ, blockchain Bitcoin ban đầu vẫn hoàn toàn mở, nhưng khi các công ty và tổ chức bắt đầu áp dụng công nghệ này, họ đã sẵn sàng hy sinh sự tin cậy và tính minh bạch để có quyền kiểm soát truy cập cũng như tùy chỉnh dễ dàng hơn.
Permissioned và Permissionless Blockchain thực sự không nên được sử dụng cho cùng một thứ. Ví dụ, mọi người có lẽ không quan tâm đến việc sử dụng một loại tiền điện tử được cấp phép (permissioned cryptocurrency), vì một trong những điểm hấp dẫn nhất của tiền điện tử là không ai có thể kiểm soát cách thức hoạt động của nó hoặc nơi nó đến. Ngược lại, một công ty như Maersk, sử dụng blockchain để theo dõi dịch vụ hậu cần vận chuyển của mình, không muốn đưa tất cả dữ liệu bí mật của mình lên một permissionless blockchain.
So sánh Permissioned và Permissionless Blockchain
Permissioned và Permissionless Blockchain có gì giống nhau?
Permissioned và Permissionless Blockchain co gì khác nhau?
Permissionless Blockchain
Permissioned blockchain
Permissioned hay permissionless blockchain tốt hơn?
Permissioned và Permissionless Blockchain có gì giống nhau?
Cả permissioned và permissionless blockchain đều có một số đặc điểm quan trọng:
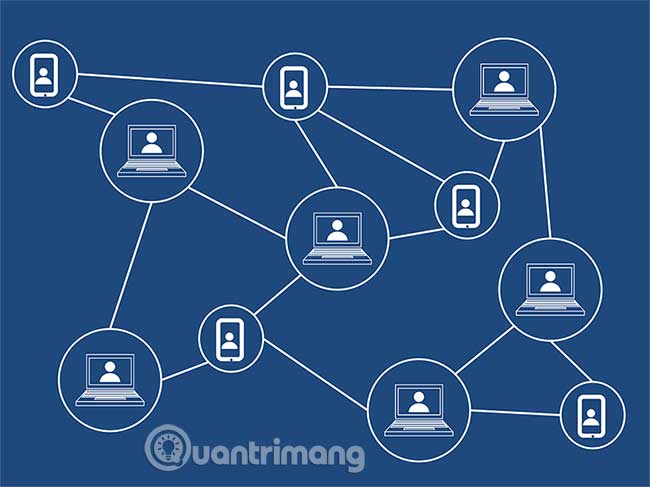
Chúng là hai distributed ledger (sổ cái phân tán), có nghĩa là có nhiều phiên bản của cùng một dữ liệu được lưu trữ ở những nơi khác nhau và được kết nối thông qua một số loại mạng.
Cả hai đều sử dụng một số hình thức của cơ chế đồng thuận (consensus mechanism), nghĩa là chúng có cách để nhiều phiên bản sổ cái đạt được sự đồng thuận về việc chúng thực sự trông sẽ ra sao.
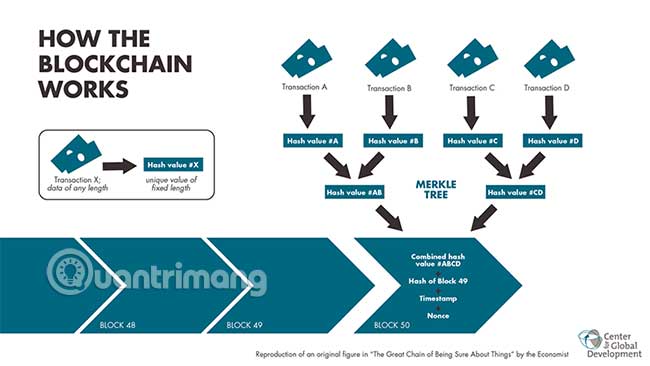
Cả hai về mặt lý thuyết đều bất biến theo nghĩa là dữ liệu chúng lưu trữ không thể bị thay đổi nếu không có đủ quyền kiểm soát mạng. Thậm chí sau đó, các block (khối) được liên kết bằng hàm băm mật mã (cryptographic hash) sẽ thay đổi nếu có bất kỳ dữ liệu nào bị thay đổi.
Nói một cách đơn giản, cả permissioned và permissionless blockchain đều sử dụng mật mã và phân cấp ở nhiều mức độ khác nhau, để lưu trữ chính xác dữ liệu ở định dạng khó hack hoặc thay đổi.
Permissioned và Permissionless Blockchain co gì khác nhau?
Permissionless Blockchain
Hầu hết các blockchain mà bạn từng nghe nói đều rơi vào loại này: Bitcoin, Ethereum, Litecoin, Dash và Monero. Tất cả những cái khác là blockchain công khai mà bất cứ ai cũng có thể giao dịch hoặc thậm chí tham gia với tư cách là validator (người xác thực).
Tất cả dữ liệu được lưu trữ trên các chuỗi này đều có sẵn công khai và các bản sao đầy đủ của sổ cái được lưu trữ trên toàn thế giới. Đó là điều khiến các hệ thống này rất khó bị hack hoặc kiểm duyệt. Không ai điều hành blockchain, không ai có thể hạn chế quyền truy cập vào nó và bạn vẫn tương đối ẩn danh vì không cần phải xác minh chính mình để nhận một địa chỉ và thực hiện giao dịch.
Loại blockchain này có xu hướng tạo ra tiếng vang vì nó có những gì làm nền tảng cho hầu hết các loại tiền điện tử và những giải pháp phân cấp thú vị nhất. Sự cường điệu này là xứng đáng, vì các permissionless blockchain công khai có khả năng cách mạng hóa những dịch vụ trước đây yêu cầu người trung gian đáng tin cậy – không chỉ là tiền tệ. Ví dụ, một blockchain bất biến của ô tô có thể cung cấp cho bạn khả năng tra cứu dữ liệu đáng tin cậy trên mọi bộ phận, hồ sơ dịch vụ và giao dịch liên quan đến một chiếc xe đã qua sử dụng, thay vì tin tưởng một người trung gian nào đó.
Tất nhiên, hệ thống này không hề hoàn hảo. Nó có thể chậm, khó xây dựng và mở rộng quy mô, quá minh bạch để lưu trữ dữ liệu nhạy cảm, khó kiểm soát truy cập, tốn nhiều năng lượng và phức tạp. Đó là lý do tại sao các permissioned blockchain đang trở thành một giải pháp phổ biến hơn cho các công ty và tổ chức muốn sử dụng blockchain để thay thế các hệ thống truyền thống.
Permissioned blockchain
Tóm lại, permissioned blockchain chỉ dành cho những người được phép truy cập. Bất cứ ai muốn xác thực các giao dịch và/hoặc xem dữ liệu trên mạng, trước tiên phải được central authority (bộ phận trung tâm, chịu trách nhiệm quản lý chính) chấp thuận.
Điều này đặc biệt hữu ích cho các ngân hàng, công ty và những tổ chức khác phải tuân thủ các quy định và không muốn mất quyền kiểm soát hoàn toàn dữ liệu. Thay vì xây dựng trên một blockchain lớn, phi tập trung như Ethereum, các đơn vị này có thể tạo ra một giải pháp tùy chỉnh, chỉ được điều hành bởi những tổ chức mà họ chấp thuận.
Hãy tưởng tượng một công ty chuyên bán dưa hấu đưa chuỗi cung ứng của họ lên một tầm cao mới:
1. Công ty quyết định xây dựng một hệ thống blockchain để theo dõi trái cây của mình từ trang trại đến cửa hàng. Họ muốn biết chính xác ai là người tham gia trong mỗi bước, vì vậy công ty này quyết định sử dụng một permissioned blockchain mà chỉ người dùng được ủy quyền mới có thể truy cập.
2. Họ xây dựng Melonchain và cung cấp cho mỗi điểm trên chuỗi cung ứng cách để truy cập và thêm dữ liệu, được xác thực bởi một mạng lưới các máy chủ do công ty điều hành. Bằng cách này, bất cứ khi nào dữ liệu về một quả dưa được ghi lại, nó có thể được tra cứu trong sổ cái và được xác minh bằng mật mã sau đó.
3. Một số dữ liệu nhất định về mỗi quả dưa hấu, như ngày và địa điểm thu hoạch, được công khai cho người tiêu dùng, trong khi các dữ liệu khác, như chuyển động chính xác trong chuỗi cung ứng, được giữ bí mật để giúp công ty duy trì lợi thế cạnh tranh.
Tiền điện tử Libra của Facebook là một ví dụ điển hình khác. Nó có thể ra mắt công chúng trong tương lai, nhưng tại thời điểm ra mắt, chỉ một số công ty được chọn, đã đầu tư và được phê duyệt, mới có quyền vận hành nó và người dùng có thể phải đăng ký bằng danh tính thực.
Những lợi thế lớn của permissioned blockchain là chúng có:
Quyền kiểm soát truy cập
Khả năng tùy biến cao
Thay đổi thời gian dễ dàng hơn để tuân thủ các quy định
Hiệu quả năng lượng tốt hơn
Khả năng mở rộng tốt hơn
Tuy nhiên, chúng cũng có những nhược điểm. Đó là:
Tập trung hơn
Ít minh bạch
Dễ bị tấn công và thao túng hơn
Dễ dàng kiểm duyệt hơn
Ít ẩn danh hơn
Permissioned hay permissionless blockchain tốt hơn?
Các permissioned và permissionless blockchain chỉ là những nhánh của cùng một công nghệ, được phát triển để đáp ứng nhiều nhu cầu khác nhau. Cả hai đều hữu ích theo cách riêng của mình, đối với hầu hết các mục đích và công nghệ khác nhau trong thực tế.
Điều này có nghĩa là những lợi ích do permissionless blockchain mang lại không trực tiếp tác động đến các hệ thống được cấp phép, vì vậy việc một công ty nói rằng mình sử dụng công nghệ blockchain không hẳn nghĩa là nó riêng tư hoặc phi tập trung hơn nhiều so với cơ sở dữ liệu truyền thống. Nắm được sự biệt giữa permissioned và permissionless blockchain là một phần khá quan trọng.
DatabaseComments Off on Reset MySQL 5.7 root password
Apr092019
sudo mysqld_safe --skip-grant-tables &
Then when paste this and hit [ENTER] mysql -uroot use mysql; update user set authentication_string=password('YOURSUPERSECRETPASSWORD') where user='root'; flush privileges; quit Restart MySQL Login Mysql and change pass set password=password('Admin321*');